- 研究計畫之背景及目的
由於網路設施在企業組織、學校單位或家庭中,均已相當普及,網際網路除了對傳統商業造成重大衝擊外,更被視為資訊溝通媒介的新典範,尤其
WWW(World Wide Web)的出現,已儼然成為全球資訊的聚集之處。網路上其它存取資訊的方法都是以字元為處理基礎,但Web郤能結合文字、超媒體、圖形、和聲音等,透過主從式電腦架構來儲存、擷取、格式化和顯示資訊【Lee et al., 1994】。雖然Web本身具備了超媒體資訊呈現、標準化格式、可輕易擴充、與跨平台分散處理的優點【Barnes and Silvestre, 1995; Liang et al., 1999】,能讓網路使用者以非線性的瀏覽方式取得所需的資訊。然而,Web網站目前正以每星期三十萬個網頁的速度持續成長中【Laudon and Laudon, 1998】。如此快速的擴散效果,一方面提供網路使用者豐富的資訊來源,但另一方面卻也引發了下列的問題【Liang et al., 1999】:1.資訊超載(Information overload):無限制膨脹的Web網站,充斥著重複、龐大與欠缺彈性的資料,當上網者欲透過Web所提供的資料來作決策時,須花費大量的時間成本來分析、過濾與判斷所蒐集到的資料,造成使用者的資訊負荷程度升高。
2.位址的迷惘(Disorientation):WWW以超鏈結語言(Hypertext language)鏈結各個文件及檔案,讓上網者可以透過更合乎其認知的方式來取得Web上的資訊。然而此種非線性的瀏覽方式,也常讓上網者迷失在龐大的網路國度中,失去方向感,不知其目前所在的位置。
3.資料品質的降低:氾濫的Web網站也讓資訊供應商(Information Provider)疲於維護資料異動的同步性,使得目前網站的資料通常是過時、不完整、甚或錯誤的資訊。
為了協助上網者管理Web上的資訊以降低使用網路的資訊負擔,實務界與學術界紛紛提出其解決之道。目前在Web上的資訊管理方法主要是以過濾與分類【Borchers et al., 1998; Chen, et al., 1998; Lincke and Schmidt, 1998; Rumpradit, 1999】的觀念為基礎,透過網站目錄分類協助使用者管理Web上資料。例如網路瀏覽器的主要廠商網景(Netscape)與微軟(Microsoft)都在其瀏覽器中加入了「我的最愛」等一些偏好記錄選項,讓使用者能依據自己的需求建立常去網站的清單。而Yahoo網站目錄能提供個人或組織登錄網頁的位置,然後再加以分類,當使用者進入其中一項目錄,鍵入一個或多個關鍵字,即可取得與關鍵字相關的網頁所在位址。此外搜尋引擎(Search Engine)亦是目前在網路上取得所需資訊的最佳方法之一,搜尋引擎不需各個網站先行登錄並標上類別即可自動來搜尋網站,他能根據使用者所輸入的關鍵字,找出一個或多個相關的Web網頁,然後依其網址和被搜尋的頻率列出符合度的排名表,例如AltaVista、Lycos和Infoseek就是這些搜尋引擎的例子。除了傳統的搜尋引擎,應用知識或meta-data來支援網路上的資訊管理亦是另一個重要趨勢【Hindas and Ravishankar, 1998; Lai and Yang, 1998; Lambrix and Shahmehri, 1998; Lassila, 1998; Lawrence and Giles, 1998; Li, 1998; Noah, 1998; Hall, 1999; Rumpradit, 1999】,目前最常用的方法是透過智慧代理人(Intelligent Agent)的方法,以預先建好的知識庫或即時的線上學習方式來協助使用者管理Web上的資料。雖然上述的這些工具已經提供了網際網路使用者管理Web資料的基礎,然而卻也具備了如下的缺點:
1.入口網站(Portal Site)雖然是一個相當不錯的資訊搜尋捷徑,然而由於每個資訊搜尋引擎的特色不一,若要鉅細靡遺可能得透過各個的搜尋引擎協助搜尋,這種土法煉鋼逐一拜訪的方法將耗費使用者寶貴的上網時間。
2.「我的最愛」選項雖能提供使用者記錄他所常去的網站,但是隨著Web網站日趨成長,「我的最愛」亦會相對的膨脹,而上網者需求多變,先前所記錄的「我的最愛」網站,可能日後少有機會再連結前往,造成「我的最愛」與Bookmark中常為過時且欠缺彈性的資料。
3.不同需求的使用者對Web網站有不同的看法,有些使用者認為Web只是資料【Noah, 1998; Rajaraman and Norvig, 1998】或文件的集合【Balasubramanian and Bashian, 1998】,有些人則將其轉換為知識作為決策的基礎。
4.搜尋引擎只滿足了使用者「目的搜尋」(Focused Search)的需求,對於「掃描」(Scanning)則無法提供協助。個體的資訊瀏覽行為可以分為「目的搜尋」與「掃描」兩大類,「目的搜尋」意指個體找尋某特定資訊的行為,在找尋之前他們已先有目標存在【Huber, 1991】。而「掃描」則是個體並不具備特殊目的只是單純的將自己暴露在資訊中,並加以瀏覽【Aguliar, 1967】。
由此看來,目前的網站目錄與搜尋引擎只能支援「目的搜尋」的工作,只有當使用者有「非常清楚的目的並想要找出特定的事實」時才能發揮功用,而瀏覽器中的「我的最愛選項」也只能提供「經常性的特定資訊來源」協助,對於資訊使用行為中所存在的「沒有預設目的單純地瀏覽資訊」與「廣泛的瀏覽資訊以決定興趣」等掃描行為並不能提供支援。因此,本研究之目的為以下兩項:
(一)探討在使用Web資訊時,使用者的掃描行為與支援需求。
目前網際網路的研究範圍已相當廣泛,如在技術層面、行銷層面、心理層面與法律層面等皆有學者探討,但對使用者資訊掃描行為與知識管理方面的研究仍尚缺乏。Vandenbosch與Huff【1997】認為資訊搜尋行為能有效提升主管的工作效率(Efficiency),然而資料掃描行為卻能同時提升效率與效能(Effectiveness)。因此,本研究的第一個目的即在探討上網者使用Web上的資訊時,其掃描的行為,並進而分析目前既有Web環境上支援Scanning資訊需求的能力及運用情形。
就Searching而言,因為有特定的目的,因此其檢索較單純,不論是完全比對或近似比對,現有系統都有很好的支援。然而,對使用者掃描的需求,目前系統所提供的支援則非常有限。主要原因乃是在掃描時為了有效減低檢索成本,需要對使用者的需求做深入的分析,並建構使用者輪廓(User Profile)再根據所建構之知識,引導掃描之位置與順序。例如,使用者可能只想要逛逛書店,但並不一定要到某家書店去找某本書,則系統須提供如何的逛書店順序及方法,就需要運用知識管理的方法對使用者可能偏好作適當的分析。因此本研究的第二個目的即是探討運用知識管理來支援使用者掃描行為的方及可能性。
(二)探討運用知識管理來支援使用者掃描行為的方法與可行性。
在今日的網路時代,目前技術所探討的重點仍集中在如何去管理網路上的資料,對於使用者瀏覽資訊的支援仍侷限在資料管理的角色,只能透管簡單的分類方式(如搜尋「我的最愛」與Yahoo)來協助使用者搜尋與管理Web資訊,對於將這些資料再做進一步的處理,來創造、擷取、並分配知識的文獻較為缺乏。因此如何透過知識管理的角度,來協助個體的資訊掃描行為,以滿足其一般性、沒有預設目的、與廣泛資訊瀏覽的行為,將是一個頗為重要的議題。
二、
研究內容說明圖一描述了網際網路資訊使用行為與知識管理的概念性架構,在此架構中,使用者不須再以傳統的資料觀點來管理
Web資訊,知識管理機制將扮演著使用者與搜尋引擎間的中介溝通者角色,其能與使用者進行個人化的接觸,可以從使用者的個人特質、先前的資訊使用行為與外在網路環境的變化狀況推論上網者的可能資訊掃描需求,並經合理推論取得上網者所欲掃描的資訊。
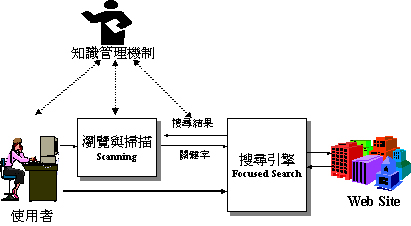
圖一、知識管理與網際網路資訊使用行為
Web上的知識管理可以由不同的觀點來探討,例如,Liang等人(1999)認為使用者角色、關注層級、管理活動與基礎技術為Web知識管理的四個角度,彙總如表一所示。在使用者的角色部份共包含了供應商、中間商與消費者,不同的使用者有不同的知識管理需求。對供應商而言,過濾、搜尋、資料更新與維護為其關心的重點,而如何整何異質性的資料則為中間商的最大考量,對消費者來言,不同的情境下會有不同的資訊需求,因此Web除了須滿足其日常操作所需外,尚須滿足其偶發的查詢。
Web的資訊可以被視成資料或文件,當使用者關注的焦點在於網頁中某一項資料時,瀏覽器只是展現資料的一個工具而已,然而若使用者欲以一宏觀的觀點來看整體文件時,網頁的資訊內容則需要被管理與整合。不同關注層級有不同的目標,在最低層中,使用者所考慮到的只是如何簡單的去抓取Web資訊,因此資料管理主要是以技術的觀點來考量。較高層級的觀點則是將資料轉換成決策的知識,而最高層級則是從資料從導出策略性的應用以獲得競爭優勢。
另一個Web知識管理的角度則是在探討管理程序上的活動,典型的管理週期包括資料定義、組織、分析、散播、利用、維護與品質保證。首先在定義階段須找出所需要的資料,並根據需求加以組織分析後,再將結果透過適當的管道予以散播。為了配合外在環境的變動,資料必須經常更新維護,並透過品質保證的活動確保資訊與知識的品質。
表一、Web知識管理的四個角度

在基礎技術部份,目前最廣為運用的即為傳統資料庫的搜尋方法,而針對大量的資訊,過濾也是常用方法之一。除此之外分類、索引、標準化與導覽亦為常用的技術,分類與索引將相似的資料或物件群集起來,標準化讓資訊整合更加容易,導覽則降低使用者在浩瀚網路資訊中迷路的機會,而運用
Meta-data來支援網路上的知識與資訊管理亦是另一個重要趨勢。
三、預期成果
本計畫所提出之網際網路資訊掃描行為與知識管理之研究結果,將可改善目前依賴搜尋的資訊使用方式,開發新的使用方法,吸引更多人運用
Web上的廣大資源。就實際應用觀點而言,未來網路資訊管理模式可依據本研究成果建構具備知識管理功能的軟體,甚至對目前的瀏覽環境及搜尋引擎的運作方式產生重大改變。本計畫所研究的網際網路資訊使用行為與知識管理,具體的貢獻將包括下列幾項:
- 就學術理論的價值而言,本研究所提出之知識管理機制與網路資訊掃描行為分析,均將透過實驗方式驗證,所得成果在撰寫研究報告後將整理成論文發表於學術期刊或會議論文集上,可供後續相關技術、資訊使用行為理論與知識管理之相關研究參考與引用。
- 就實際應用觀點而言,
參考文獻
Aguliar, F. J., Scanning the Business Environment, MacMillan, New York, 1967.
Balasubramanian, V. and Bashian, A., “Document Management and Web Technologies: Alice Marries the Mad Hatter,” Communication of the ACM, Vol. 31, No. 7, 1998, pp. 107-114.
Borchers, A. et al., “Ganging Up on Information Overload,” Computer, January, pp. 106-108.
Chen, H. et al., “An Intelligent Personal Spider (agent) for Dynamic Internet/Intranet Searching,” Decision Support Systems, Vol. 23, No. 1, 1998, pp.41-58.
Hall, R J., “How to Avoid Unwanted Email,” Communication of the ACM,” Vol. 41, No.3, 1998, pp. 88-95.
Hindas, N. and Raivshankar, C. V., “ Managing Metadata for Distributed Information Services,” Proceedings of HICSS-31, Vol. IV, 1998, pp. 513-512.
Huber, G. P., “Organizational Learning: The Contributing Process and the Literatures,” Organization Science, 2:1, 1991, pp. 88-115.
Lai, H. and Yang, T.C., “A System Architecture ofr Intelligent-Guided Browsing on the Web,” Proceedings of HICSS-31, Vol. IV, 1998, pp.423-432.
Lambrix, P. and Shahmehri, N., “TRIFU: The Right Information for You,” Proceedings of HICSS-31, Vol. IV, 1998, pp. 505-512.
Lassila, O., “Web Metadata: A Matter of Semantics,” IEEE Internet Computing, Vol. 2, No. 4, 1998, pp.30-37.
Lawrence, S. and Giles, C. L., Context and Page Analysis for Improved Web Search,” IEEE Inernet Computing, Vol. 2, No. 4, July-August, pp.38-46.
Liang, T. P., Shaw, J. P., and Wei, C. P., “A Framework for Managing Web Information: Current Research and Future Direction,” Proceedings of the 32nd Hawaii International Conference on System Sciences, 1999.
Liang, T. P., and Huang, J. S., “An Empirical Study on Consumer Acceptance of Products on Electronic Markets: A Transaction Cost Model,” Decision Support Systems, 1998.
Liang, T. P. and Huang, J. S., “A Framework for Applying Intelligent Agents to Support Electronic Commerce,” Decision Support Systems,1999.
Lincke, D. and Schmidt, B., “Mediating Electronic Product Catalogs,” Communications of the ACM, Vol. 41, No. 7, pp. 86-88.
Noah W. W., “The Integration of the World Wide Web and Intranet Data Resources,” Proceedings of HICSS-31, Vol. IV,1998, pp. 496-503.
Rajaraman, A. and Norvig, P., “Virtual Database Technology: Transforming the Internet into a Database,” IEEE Internet Computing, Vol. 2 No. 4, 1998, pp.55-58.
Rumpradit, C., “Navigation Cues on User Interface Design to Product Better Information Seeking on the World Wide Web,” Proceedings of HICSS-32, 1999, Hawaii.
Vandenbosch B. and Huff, S. L., “Searching and Scanning: How Executives Obtain Information From Executive Information Systems,” MIS Quarterly, Vol. 21, No. 1, March 1997.