假設資料項的初值如下:X = Y = Z = A = B = C = 0,請問系統復原後,各資料項的值為何?
| 習題12-1 |
|---|
假設你是公司裡的資料庫管理員 (DBA),公司裡大部分的資料庫應用系統都是執行資料庫的交易,每一筆交易裡包含了記錄的增刪和修改,以及簡單的查詢。你的上司要求你調整一些DBMS 的參數,以提高交易的執行效率。假設你有以下的參數,請描述調整這些參數會如何影響交易的執行效率。 |
| 習題12-2 | ||||
|---|---|---|---|---|
考慮以下的交易:
假設資料項的初值如下:X = Y = Z = 0,且記憶體夠大,所以作業系統並不主動將緩衝區的資料頁或追蹤記錄寫回硬碟。 請描述在時間點1, 3, 5, 7 的運算動作執行後,資料頁和系統追蹤檔在記憶體和硬碟的內容。 |
| 習題12-3 |
|---|
| 考慮以下的交易排程: 假設資料項的初值如下:X = Y = Z = A = B = C = 0,請問系統復原後,各資料項的值為何? |
| 習題12-4 |
|---|
考慮以下的交易排程: 假設資料項的初值如下:X = Y = Z = A = B = C = 0,且記憶體夠大,所以作業系統並不主動將緩衝區的資料或追蹤記錄寫回硬碟。 請列出在以下時機的資料頁和系統追蹤檔在記憶體和硬碟的內容。 1. 還未執行時 2. 執行 commit (T1) 後 3. 執行checkpoint 後 4. 執行到系統當機前 5. 系統復原後 |
| 習題12-5 |
|---|
考慮以下的交易排程: 其中 flush(Y) 表示將記憶體裡資料頁Y 的值寫回硬碟。假設資料項的初值如下:X = Y = Z = A = B = C = 0,且記憶體夠大,所以作業系統並不主動將緩衝區的資料或追蹤記錄寫回硬碟。 請列出在以下時機的資料頁和系統追蹤檔在記憶體和硬碟的內容。 1. abort (T2) 前 2. abort (T2) 後 3. flush (Y) 後 4. 系統復原後 |
| 習題12-6 | ||||
|---|---|---|---|---|
考慮T1 和T2 兩個交易如下:
1. 試列出一個T1 和T2 的排程,該排程是嚴格但非可順序的排程。 2. 試列出一個T1 和T2 的排程,該排程是無連鎖駁回但非嚴格的排程。 3. 試列出一個T1 和T2 的排程,該排程是可復原但非無連鎖駁回的排程。 4. 試列出一個T1 和T2 的排程,該排程是非可復原的排程。 |
| 習題12-7 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
請畫出以下每一個排程的可順序圖並判別何者為可順序的排程。
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 習題12-8 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 假設DBMS 的交易排程模組採用嚴格兩階段鎖定法來進行交易排程。 1. 請問以下的非嚴格排程可能發生嗎?若否,則交易排程模組會將其運算次序改變為何?
2. 請問以下的排程可能發生嗎?若否,則交易排程模組會將其運算次序改變為何?
3. 請問以下的非可順序排程可能發生嗎?若否,則交易排程模組會將其運算次序改變為何?
4. 你認為這個排程模組是否一定產生嚴格且可順序的排程?為什麼? |
| 習題12-9 |
|---|
| 請舉例說明SQL2 的隔離等級之涵義 (READ NCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABILITY)。 |
| 習題12-10 |
|---|
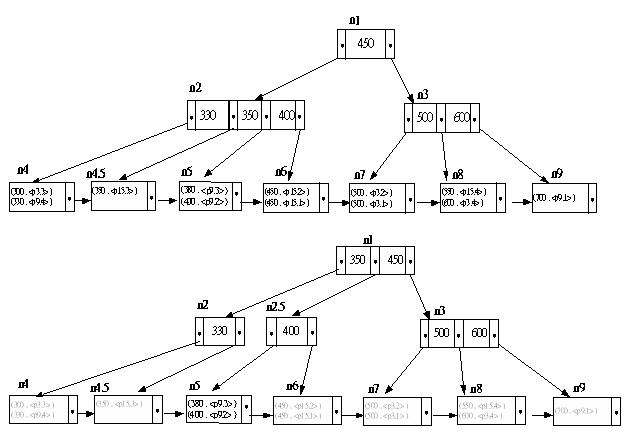
| 假設一筆資料庫交易裡的某一個查詢句在處理時需使用到某一個B+-tree,為顧及資料的一致性,該B+-tree 的節點存取也必須有限制。我們可以採用鎖定的機制 (請參考第五節的說明)。一種可能的方式如下: 1. 查詢某一個索引值:先由根節點開始,將該節點的鎖定狀態設為 SHARED_LOCKED,然後找尋下一層的節點,再將該節點的鎖定狀態設為 SHARED_LOCKED 並將上一層的節點的鎖定狀態設為UNLOCKED。直到找到所需的索引值和記錄指標為止。 2. 新增某一個屬性值和記錄指標配對:先由根節點開始,將該節點的鎖定狀態設為SHARED_LOCKED,然後找尋下一層的中間節點,再將該節點的鎖定狀態設為SHARED_LOCKED 並將上一層的節點UNLOCKED,直到葉節點時,再將該節點的鎖定狀態設為EXCLUSIVE_LOCKED,並修改該葉節點 (新增一個索引值和記錄指標配對)。若該葉節點不夠大時,則再新增一個葉節點以便容納,並將其父節點的鎖定狀態設為EXCLUSIVE_LOCKED 以便修改該父節點。同樣的,若該父節點又不夠大時,則按同樣方法新增節點和修改其父節點。 請討論並舉例說明這樣的方法,這樣的方式有何缺點? |